
In an era where data is the new gold, the tension between harnessing powerful artificial intelligence models and protecting user privacy has never been greater. Centralized machine learning approaches require pooling vast amounts of sensitive data in cloud servers, raising concerns about data breaches, regulatory compliance, and user trust. Federated learning emerges as a groundbreaking paradigm that flips the script: instead of sending raw data to a central server, individual devices collaborate to train a shared model locally, sending only model updates for aggregation. This decentralized approach promises to unlock powerful insights while keeping personal data securely on-device. In this comprehensive guide, we delve into the fundamentals of federated learning, explore its inner workings, highlight key benefits and challenges, survey cutting-edge applications, and cast an eye toward future trends in privacy-preserving AI.
What Is Federated Learning?
Federated learning is a machine learning technique that enables edge devices—such as smartphones, tablets, IoT sensors, and other endpoints—to collaboratively train a global model without sharing raw data. Each device uses its local dataset to compute model updates, then transmits only those parameter changes or gradients to a central server. The server aggregates these updates, refines the global model, and redistributes the improved parameters back to the participants. This iterative process continues until the model achieves desired accuracy. By keeping personal data on-device and exchanging only encrypted model updates, federated learning addresses privacy concerns, meets stringent data protection regulations like GDPR, and reduces the risk associated with centralized data storage.
How Federated Learning Works: A Step-by-Step Breakdown
The federated learning workflow can be summarized in four key phases:
- Initialization: The central server initializes a global model and broadcasts its weights to a set of selected client devices. Clients may be chosen randomly or based on availability and network conditions.
- Local Training: Each client loads the current global model and trains it locally on private data for one or more epochs. This yields updated model parameters based solely on local examples, such as user interactions, device logs, or sensor readings.
- Secure Aggregation: Clients encrypt or mask their parameter updates and transmit them to the central server. Techniques like Secure Multiparty Computation (SMPC) or Differential Privacy can be employed to prevent reverse engineering of individual datasets from gradients.
- Global Model Update: The server decrypts (or directly aggregates masked updates) to compute an average or weighted sum of the received gradients. It then updates the global model weights accordingly and distributes the new model to clients for the next round of training.
This loop continues until convergence criteria—such as target accuracy or maximum communication rounds—are met. Key optimizations, including adaptive learning rates, dynamic client selection, and compression of model updates, can help address challenges like limited bandwidth and heterogeneous hardware capabilities.
Key Benefits of Federated Learning
Federated learning offers multiple advantages over traditional approaches, driving its adoption across industries:
- Enhanced Privacy: Raw data never leaves the device, minimizing exposure to external threats. Techniques like differential privacy can further obfuscate individual contributions to the model.
- Regulatory Compliance: By keeping data in its origin jurisdiction, organizations can more easily comply with data sovereignty laws and industry regulations such as GDPR or HIPAA.
- Reduced Bandwidth Usage: Transmitting model updates instead of entire datasets significantly lowers network traffic, which is crucial for large-scale deployments across thousands or millions of devices.
- Personalization: Local training on device-specific data enables personalized experiences, from smart keyboard predictions to tailored health recommendations, without compromising user privacy.
- Robustness to Central Failures: Decentralized training reduces single points of failure. If one device goes offline, others can continue contributing to the global model update.
Challenges and Emerging Solutions
Despite its promise, federated learning introduces unique technical hurdles that researchers and practitioners are actively addressing:
- System Heterogeneity: Client devices vary in computational power, memory, and connectivity. Solutions include adaptive client selection, asynchronous update protocols, and lightweight model architectures designed for edge deployments.
- Communication Efficiency: Frequent transmission of model updates can strain networks. Gradient compression, update quantization, and sparse communication strategies help reduce overhead.
- Privacy Attacks: Malicious actors may attempt to reconstruct private data from gradients or launch poisoning attacks. Secure aggregation, differential privacy, and robust aggregation algorithms mitigate these risks.
- Scalability: Coordinating millions of devices in real time poses orchestration challenges. Hierarchical federated learning architectures and edge server proxies enhance scalability and manage contention.
- Model Drift: Non-iid (non–independently and identically distributed) data across clients can lead to model divergence. Techniques such as protonorm, adaptive federated optimizers, and personalized model fine-tuning help maintain performance across diverse data distributions.
Real-World Applications and Use Cases
Federated learning is gaining traction in various sectors that handle sensitive data or require on-device intelligence:
- Mobile Keyboard Prediction: Tech giants leverage federated learning to improve next-word suggestions and autocorrect models by training on user typing patterns without uploading personal text logs.
- Healthcare and Medical Research: Hospitals and research centers collaborate on training diagnostic models using patient data that remains behind institutional firewalls, accelerating breakthroughs while respecting privacy constraints.
- Smart Home Devices: Federated learning enables voice assistants and IoT appliances to adapt to user behavior locally, offering personalized services without continuously streaming private audio or usage logs to the cloud.
- Autonomous Vehicles: Fleets of self-driving cars can jointly improve object detection and navigation models by sharing aggregated learning without exchanging raw sensor recordings from individual journeys.
- Financial Services: Banks and insurers apply federated learning to detect fraud patterns across institutions while safeguarding proprietary customer data and complying with strict regulatory guidelines.
Future Trends and Research Directions
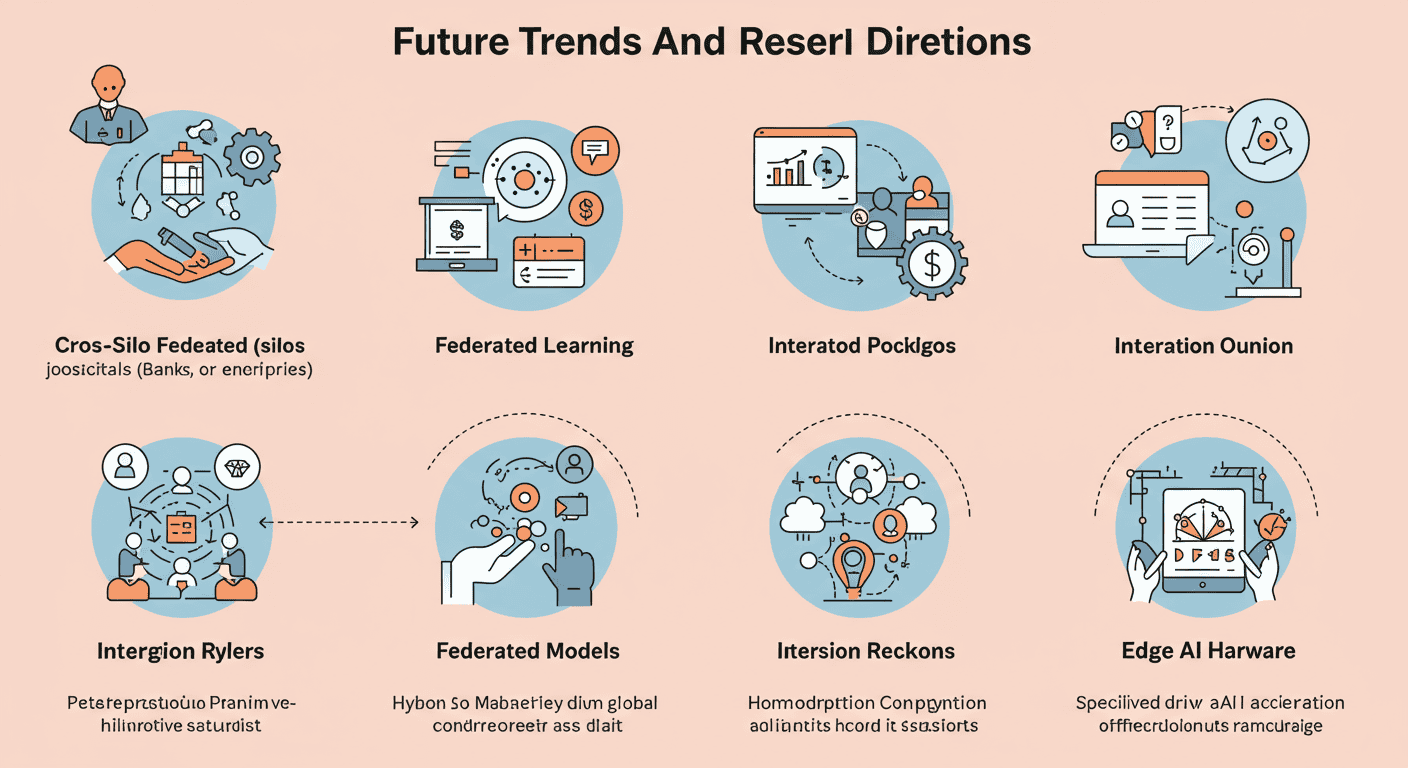
Federated learning is rapidly evolving, and several emerging trends are set to shape its trajectory:
- Cross-Silo Federated Learning: Collaboration among organizations (silos) such as hospitals, banks, or enterprises allows them to jointly train models on highly sensitive data while each retains full control over its dataset.
- Personalized Federated Models: Hybrid approaches that combine global model training with on-device fine-tuning promise both broad generalization and local personalization, catering to unique user behaviors.
- Integration with Blockchain: Decentralized ledgers can enhance transparency, auditability, and incentive mechanisms in federated learning ecosystems, ensuring fair reward distribution among participants.
- Advanced Privacy Mechanisms: Innovations in secure multi-party computation, homomorphic encryption, and zero-knowledge proofs will strengthen privacy guarantees without compromising model accuracy.
- Edge AI Hardware: Specialized AI accelerators and neural processing units optimized for federated workloads will drive more efficient on-device training and inference at scale.
Conclusion
As organizations strive to leverage artificial intelligence responsibly, federated learning stands out as a transformative approach that reconciles data-driven innovation with stringent privacy requirements. By distributing model training across edge devices and aggregating encrypted updates, federated learning minimizes data exposure, reduces network costs, and delivers personalized intelligence at scale. While challenges around communication efficiency, security, and heterogeneity remain, ongoing research and industry collaboration continue to push the boundaries of what is possible. From mobile keyboards to autonomous vehicles, federated learning is already making an impact—and its role in shaping the future of AI is set to grow even stronger. Embracing this paradigm today can help enterprises build trust with users, comply with evolving regulations, and unlock new frontiers of data-driven value.
Learn more about: AI-Driven Synthetic Data Generation: A Game Changer for Data Privacy and Model Training









Leave a Reply